Inside Meta’s Synthetic-Data Kit for Llama Fine-Tuning
Synthetic data now underwrites frontier LLMs and fine-tuning.
Berkeley’s TinyZero1 and Sky-T12 show you can teach 3-billion to 32-billion parameter models sophisticated reasoning for $30 – $450 by distilling curated DeepSeek-style traces, and Meta’s new synthetic-data-kit3 packages the same generate-and-curate pipeline.
In this post I break down each stage of the toolkit, so you can see exactly how high-quality synthetic datasets are built and exported for fine-tuning.
What the tool does
Let me repeat once again what the tool is all about:
Synthetic-data-kit is a toolkit for generating high-quality synthetic datasets to fine-tune Large Language Models.
To do that, the tool exposes a simple CLI interface to the user with the following commands:
- ingest: Converts various file formats (PDF, HTML, YouTube, DOCX, PPT, TXT) into clean text using format-specific parsers
- create: Generates synthetic training data in different formats: - Question-answer pairs - Chain-of-thought reasoning examples - Summaries
- curate: Rates and filters generated content using the same LLM as a judge, removing low-quality examples based on a configurable quality threshold
- save-as: Converts filtered content to various fine-tuning formats (JSONL, Alpaca, ChatML) compatible with different training pipelines
The CLI commands are part of a four-step workflow for generating synthetic datasets that's not that different than any typical ETL pipelines you've seen out there. We have:
- Extraction: In the form of ingesting data from various file formats.
- Transformation: By creating synthetic data in different formats.
- Load: Saving the datasets into fine-tuning formats for downstream training pipelines.
There's also another interesting parallel here with more traditional DE terminology. The curation part is similar to the QA data quality part of the data pipelining work.
Enough with drawing connections with data engineering!
Let's see how these functions work and how, when put together, they provide a complete toolkit for generating synthetic data.
How the sausage is made
The tool is created by Meta so I guess no one would be surprised to learn that all the content around it is assuming Llama as the model being used.
For that reason, and to make it easy for people to run it locally, it expects a local vLLM4 that serves a model, preferably of the Llama family that will be used in the generation flow.
[!Important] The tool is using the OpenAI-compatible API provided by VLLM for inference. It connects to the endpoint at http://localhost:8000/v1/chat/completions by default (configurable in config.yaml).
Having said that, it's obvious that extending the tool to connect to other inference engines shouldn't be too hard.
Ingest: parsing the data
What I found beautiful about the project is that it comes with a good set of supported formats for ingesting data. When we talk about data here we primarily mean unstructured data of course so expect to see PDFs, audio files, etc. Here's what and how is supported:
- PDF: Uses pdfminer's extract_text function to extract text content.
- HTML: Uses BeautifulSoup4, parses HTML, removes script/style elements, and extracts clean text. Supports both local files and remote URLs.
- YouTube: Uses pytube, youtube-transcript-api, extracts video transcript and combines with metadata (title, author).
- DOCX: Uses python-docx, extracts text from paragraphs and tables.
- PPTX: Uses python-pptx, extracts text from slides including titles and text shapes.
- TXT: Uses standard Python, nothing fancy here.
Of course it's a well designed API and you will find common interfaces that all the parsers share etc.
[!Important] The goal of the ingestion function is to take whatever input data and always export text
Example:
synthetic-data-kit ingest research_paper.pdf
- The system determines the file type by extension (.pdf) and selects the appropriate parser
- The Parser loads the file using the appropriate library and extracts the text content
- The extracted text is saved to the output directory with a .txt extension
- The path to the output file is returned and displayed to the user
And that's it! You have your data ingested!
Now let's move to the more fancy stuff where we start interacting with the models.
Create: QA, CoT, summaries
After you have generated some textual data, you are ready to start generating synthetic data based on that. It's important though to make clear what we mean by synthetic data here.
The tool is focused on data that is used for fine tuning LLMs. What does that mean?
It means that our original data that we have ingested will be used to create pairs of questions and answers. What we want to do is to use the data we have to generate valid pairs of questions and answers that then can be used to fine tune a model. By doing that we hope that the fine-tuned model will be better at answering questions related to the data we used.
Based on that, here are the types of synthetic data the tool supports:
- QA Pairs: Pairs of questions and answers based on the data
- QA Pairs with CoT: QA Pairs together with reasoning traces to support the answers
- Summary: Just a summary of the whole document
And here are the steps the tool will go through for the case of creating QA Pairs.
synthetic-data-kit create document.txt --type qa
| Step | What it does |
|---|---|
| Init | Sets up the CLI context and connects to your vLLM endpoint |
| Summary | Generates a low-temperature, document-wide summary |
| Chunk | Splits the source text into ≈ 4 K-char chunks and allocates a QA-pair quota per chunk |
| QA-pair gen | Prompts the model with qa_generation to emit JSON QA pairs (optionally CoT) |
| Consolidate | Merges QA pairs from all chunks and attaches the document summary |
| Save | Writes the result to *.qa.json (or .cot.json / .summary.json) |
And we are done!
If you wonder why the tool has to calculate the number of QAs to be generated, that's because the user requests a total number of pairs and the tool tries to split that number among the chunks that will be processed.
And here are some of the prompts used.
Summary prompt:
summary: |
Summarize this document in 3-5 sentences, focusing on the main topic and key concepts.
QA Pair Generation Prompt
qa_generation: |
Create {num_pairs} question-answer pairs from this text for LLM training.
Rules:
1. Questions must be about important facts in the text
2. Answers must be directly supported by the text
3. Return JSON format only:
[{{
"question": "Question 1?",
"answer": "Answer 1."
}},
{{
"question": "Question 2?",
"answer": "Answer 2."
}}]
Text:
{text}
You can find the rest in the config.yaml file and of course the system is configurable so you can add your own or edit the existing ones.
What about CoT?
Chain of Thought traces are generated by using an existing QA pair and request the model to generate reasoning traces in a step by step format.
This is a bit different than some other tools that are using reasoning models that also return the reasoning traces and extract that.
I assume here that if you would like to use a model that returns the traces back, the work to be done won't be significant but keep in mind that out of the box the tool does not use that feature of reasoning models.
Curate: let the model be the judge
The curation part is interesting because it's the part that a lot can be improved or go very wrong.
The goal here is to maximize the quality of the dataset you are creating, when the data is synthetic and you don't rely on experts to annotate the data, this is not an easy task.
Here's what's going on here:
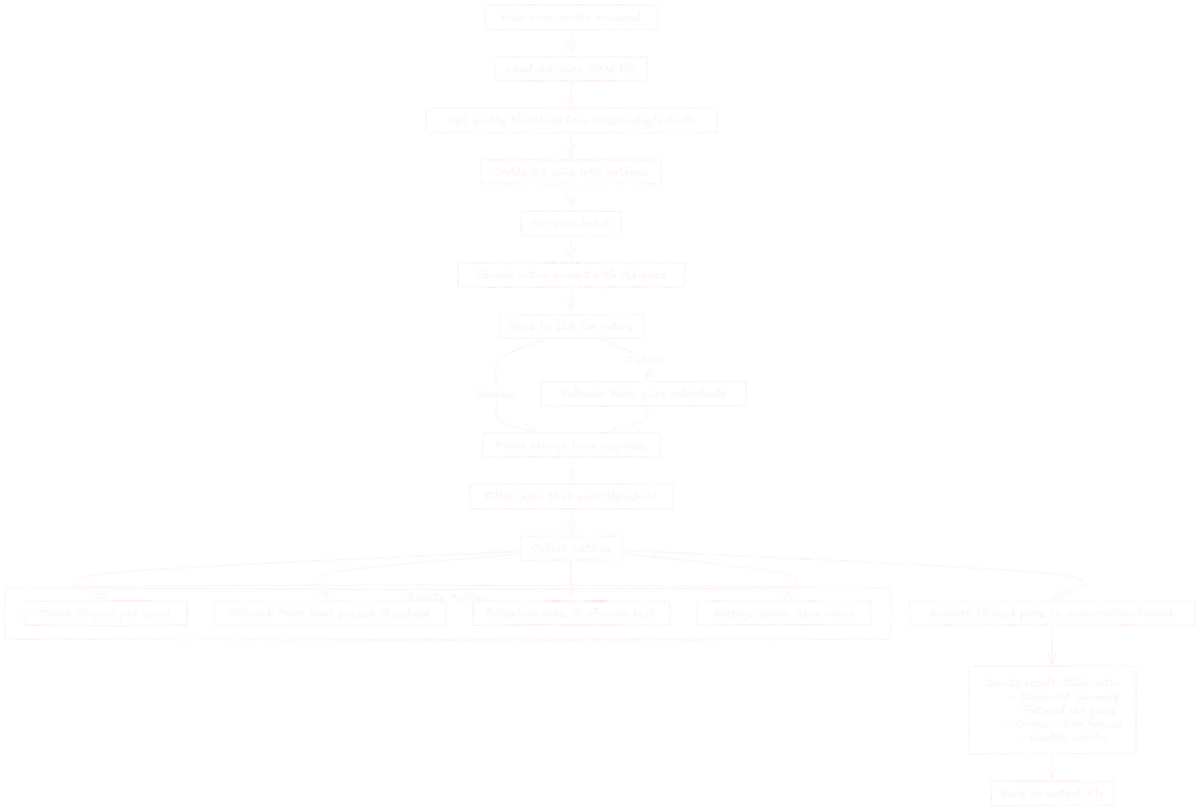
If you are interested in the prompt for QA, here's how it looks like:
qa_rating: |
Rate each question-answer pair on a scale from 1-10, based on:
- Accuracy (0-3): factual correctness
- Relevance (0-2): relevance to content
- Clarity (0-2): clear language
- Usefulness (0-3): value for model learning
YOU MUST RETURN A VALID JSON OBJECT OR ARRAY WITH THIS EXACT SCHEMA:
{{
"question": "Exact question text",
"answer": "Exact answer text",
"rating": 8
}}
OR FOR MULTIPLE PAIRS:
[{{"question": "Q1", "answer": "A1", "rating": 8}},
{{"question": "Q2", "answer": "A2", "rating": 9}}]
*** YOUR RESPONSE MUST BE VALID JSON AND NOTHING ELSE - NO EXPLANATION, NO MARKDOWN ***
QA pairs to rate:
{pairs}
And that's it!
My guess here is that you want to use a different model, hopefully a stronger one, for the curation phase.
To quickly summarize curation, the user:
- Load the generated QA (or CoT/Summary) file.
- Split pairs into manageable batches.
- Rate each batch with a stronger LLM using the qa_rating prompt.
- Filter pairs below the user-defined quality threshold.
- Report metrics — total, kept, retention %, average score — and emit the curated dataset.
Save-as: ship to your downstream training pipeline
Assuming we are happy with our data, we now want to start the fun and scientific part of training or fine tuning the model. But having just text or JSON is not enough.
Models expect specific formats for fine tuning and training so we have to do a little bit more work to get ready and here's where the last functionality of the tool is useful at.
The save-as command is the final step in the pipeline, preparing the data in the exact format needed for different fine-tuning workflows and frameworks, making it ready to use without additional preprocessing.
For this functionality, the tool expects as input the output of the previous steps in JSON and it supports the following output formats:
- jsonl: Simple line-by-line JSON format (default)
- alpaca: Format with "instruction", "input", and "output" fields
- ft: OpenAI fine-tuning format with role-based messages
- chatml: Chat format with system, user, and assistant messages
There are also two options in terms of storage formats:
- JSON
- HuggingFace Dataset in Arrow format
What is next
Next, the world is your oyster. You can use some popular fine-tuning services for LLMs or maybe you run your own datacenter for training frontier models or maybe use something like unsloth5.
Regardless of what you will do next, the data you have created is going to be the most important factor in the success of what you're doing and for this reason, I expect someone who will be doing this seriously or even hobby-seriously, to go back to the tool again and again.